Extreme Learning Machines (ELM): Filling the Gap between Frank Rosenblatt's Dream and John von Neumann's Puzzle
- Network architectures: a homogenous hierarchical learning machine for partially or fully connected multi layers / single layer of (artifical or biological) networks with almost any type of practical (artifical) hidden nodes (or bilogical neurons).
- Learning theories: Learning can be made without iteratively tuning (articial) hidden nodes (or biological neurons).
- Learning algorithms: General, unifying and universal (optimization based) learning frameworks for compression, feature learning, clustering, regression and classification. Basic steps:
1) Learning are made layer wise (in white box)
2) Randomly generate (any nonliear piecewise) hidden neurons or inheritate hidden neuorns from ancestors
3) Learn the output weights in each hidden layer (with application based optimization constraints)
Unlike conventional learning theories and tenets, our doubts are "Do we really need so many different types of learning algorithms (SVM, BP, etc) for so many different types of networks (different types of SLFNs (RBF networks, polynomial networks, complex networks, Fourier series, wavelet networks, etc) and multi-layer of architecfures, different types of neurons, etc)? "
Is there a general learning scheme for wide type of different networks (SLFNs and multi-layer networks)?
Neural networks (NN) and support vector machines (SVM) play key roles in machine learning and data analysis. Feedforward neural networks and support vector machines are usually considered different learning techniques in computational intelligence community. Both popular learning techniques face some challenging issues such as: intensive human intervene, slow learning speed, poor learning scalability.
It is clear that the learning speed of feedforward neural networks including deep learning is in general far slower than required and it has been a major bottleneck in their applications for past decades. Two key reasons behind may be: 1) the slow gradient-based learning algorithms are extensively used to train neural networks, and 2) all the parameters of the networks are tuned iteratively by using such learning algorithms.
Essential considerations of ELM:
For example, ELM not only achieves state-of-art results but also shortens the training time from days (spent by deep learning) to several minutes (by ELM) in MNIST OCR dataset, traffic sign recognition and 3D graphic application, etc. It’s difficult to achieve such performance by conventional learning techniques.
Datasets |
Learning Methods |
Testing Accuracy |
Training Time |
|---|---|---|---|
MNIST OCR |
ELM (multi hidden layers, unpublished) | ~99.6% | several minutes |
ELM (multi hidden layers, ELM auto encoder) |
99.14% |
281.37s (CPU) |
|
Deep Belief Networks (DBN) |
98.87% |
5.7 hours (GPU) |
|
| Deep Boltzmann Machines (DBM) | 99.05% |
19 hours (GPU) |
|
Stacked Auto Encoders (SAE) |
98.6% |
> 17 hours (GPU) |
|
Stacked Denoising Auto Encoders (SDAE) |
98.72% |
> 17 hours (GPU) | |
3D Shape Classification |
ELM (multi hidden layers, local receptive fields) | 81.39% |
306.4s (CPU) |
Convolutional Deep Belief Network (CBDN) |
77.32% |
> 2 days (GPU) |
|
Traffic sign recognition (GTSRB Dataset) |
HOG+ELM | 99.56% | 209s (CPU) |
| CNN+ELM (Convolutional neural networks (as feature learning) + ELM (as classifer)) | 99.48% | 5 hours (CPU) | |
Multi-column deep neural network (MCDNN) |
99.46% |
> 37 hours(GPU) |
There are many types of SLFNs including feedforward networks (e,g., sigmoid networks), RBF networks, SVM (considered as a special type of SLFNs), polynomial networks, Fourier series, wavelet, etc. Those are considered separate and different algorithms before. However, ELM actually fills gaps among them and proposes that it needn’t have different learning algorithms for different SLFNs if universal approximation and classification capabilities are considered.
References:
[1] G.-B. Huang, L. Chen and C.-K. Siew, “Universal Approximation Using Incremental Constructive Feedforward Networks with Random Hidden Nodes”, IEEE Transactions on Neural Networks, vol. 17, no. 4, pp. 879-892, 2006.
[2] G.-B. Huang and L. Chen, “Convex Incremental Extreme Learning Machine,” Neurocomputing, vol. 70, pp. 3056-3062, 2007.
Ridge regression theory, linear system stability, matrix stability, Bartlett’s neural network generalization performance theory, SVM’s maximal margin, etc are usually considered different before ELM. Especially Bartlett’s neural network generalization performance were seldom adopted in training networks before. ELM adopts Bartlett’s theory in order to guarantee its generalization performance. ELM theories and philosophy show that those earlier theories are actually consistent in machine learning.
References:
[3] G.-B. Huang, H. Zhou, X. Ding, and R. Zhang, “Extreme Learning Machine for Regression and Multiclass Classification,” IEEE Transactions on Systems, Man, and Cybernetics - Part B: Cybernetics, vol. 42, no. 2, pp. 513-529, 2012.
[4] G.-B. Huang, “An Insight into Extreme Learning Machines: Random Neurons, Random Features and Kernels,” Cognitive Computation, vol. 6, pp. 376-390, 2014.
Do we really need to train multi hidden layers of feedforward networks by iteratively adjusting hidden neurons? Should feedforward neural networks be considered as a blackbox as considered in the past six decades?
Different from BP and SVM which consider multi-layer of networks as a black box, ELM handles both SLFNs and multi-hidden-layer of networks similarly. ELM considers multi-hidden-layer of networks as a white box and trained layer-by-layer. However, different from Deep Learning which requires intensive tuning in hidden layers and hidden neurons, ELM theories show that hidden neurons are important but need not be turned (for both SLFNs and multi-hidden-layer of networks) , learning can simply be made without iteratively tuning hidden neurons.
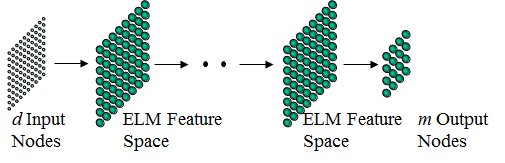
Different from Deep Learning, all the hidden neurons in hierarchical ELM as a whole are not required to be iteratively tuned
References:
[5] J. Tang, C. Deng, and G.-B. Huang, “Extreme Learning Machine for Multilayer Perceptron,” IEEE Transactions on Neural Networks and Learning Systems, May 2015.
[6] G.-B. Huang, Z. Bai, L. L. C. Kasun, and C. M. Vong, “Local Receptive Fields Based Extreme Learning Machine,” IEEE Computational Intelligence Magazine, vol. 10, no. 2, pp. 18-29, 2015.
[7] L. L. C. Kasun, H. Zhou, G.-B. Huang, and C. M. Vong, “Representational Learning with Extreme Learning Machine for Big Data,” IEEE Intelligent Systems, vol. 28, no. 6, pp. 31-34, December 2013.
ELM theories show that hidden neurons are important but need not be tuned in many applications (e.g, compressive sensing, feature learning, clustering, regression and classification). In theory, such neurons can be almost any nonlinear piecewise continuous neurons including hundreds of types of biological neurons of which the exact math modelling may be unknown to human being. ELM theory was confirmed in biological systems in 2013.
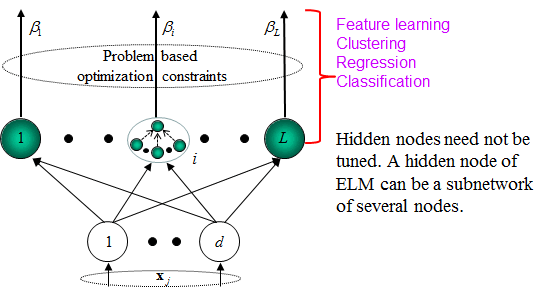
Rosenblatt dreamed that perceptron can be "the embryo of an electronic computer that will be able to walk, talk, see, write, reproduce itself and be conscious of its existence” and Neumann felt puzzled on why ``an imperfect (biological) neural network, containing many random connections, can be made to perform reliably those functions which might be represented by idealized wiring diagrams.” There exists significant gap between them. From ELM theories point of view, the entire multi layers of networks (artificial neural network or biological networks) are structured and ordered, but they may be seemingly ‘‘messy’’ and ‘‘unstructured’’ in a particular layer or neuron slice. ‘‘Hard wiring’’ can be randomly built locally with full connection or partial connections. Coexistence of globally structured architectures and locally random hidden neurons happen to have fundamental learning capabilities of compression, feature learning, clustering, regression and classification. This may have addressed John von Neumann’s puzzle. Biological learning mechanisms are sophisticated, and we believe that ‘‘learning without tuning hidden neurons’’ is one of the fundamental biological learning mechanisms in many modules of learning systems. Furthermore, random hidden neurons and ‘‘random wiring’’ are only two specific implementations of such ‘‘learning without tuning hidden neurons’’ learning mechanisms.
References:
[8] O. Barak, M. Rigotti, S. Fusi, "The sparseness of mixed selectivity neurons controls the generalization-discrimination trade-off," Journal of Neuroscience, vol. 33, no. 9, pp. 3844-3856, 2013
[9] M. Rigotti, O. Barak, M. R. Warden, X.-J. Wang, N. D. Daw, E. X. Miller, S. Fusi, "The importance of mixed selectivity in complex cognitive tasks," Nature, vol.497, pp. 585-590, 2013
[10] S. Fusi, E. K Miller, and M. Rigotti, "Why neurons mix: high dimensionality for higher
cognition," Current Opinion in Neurobiology, vol. 37, pp. 66-74, 2015
[11] G.-B. Huang, “What are Extreme Learning Machines? Filling the Gap between Frank Rosenblatt's Dream and John von Neumann's Puzzle,” Cognitive Computation, vol. 7, pp. 263-278, 2015.
[12] L. L. C. Kasun, H. Zhou, G.-B. Huang, and C. M. Vong, “Representational Learning with Extreme Learning Machine for Big Data,” IEEE Intelligent Systems, vol. 28, no. 6, pp. 31-34, December 2013.
WCCI2020/IJCNN2020 Special Sessions on Extreme Learning Machines
19-24 July 2020, Glasgow, Scotland, UK
Google Scholar just annouced Classic Papers: Articles That Have Stood The Test of Time
Top 10 articiles in Aritificial Intelligence
Top 1 is on deep learning. ELM was listed Top 2 in the list
Beautiful similarities between ELM , Darwinism, and Brownian motions
A talk on AI in a high middle school
WHO behind the malign and attack on ELM, GOAL of the attack and
ESSENCE of ELM